分布式可观测性,链路追踪与OpenTelemetry
本文最后更新于 2025年1月17日 中午
一些写在前面的碎碎念:
在 Amazon 已经实习了三个多月,很幸运没有被分配到做业务的活,想到实习的内容还是有一定价值的,值得我将其记录并进行一定的输出。
本来想着等实习结束后再进行总结,但是最近发生的一些事情让我意识到许多事情不要过分计划,有了想法就尽快 Demo 出来,哪怕只是一些零散的东西。
因此有了这篇博客,在总结输出的过程顺便让我理一理思绪。看心情可能会分为很多章,由于我做的内容仅仅只涉及到链路追踪(Tracing)部分,因此不对其他(Logging、Metrics)做过分详细的介绍。
由于我也是从 0 开始的小白,不保证内容的深刻程度。
- 在概念部分,我尽量引用别人的文字和图,辅以部分个人理解,以确保内容的可靠性。
- 在技术部分,我会更多的阐述一些 OpenTelemetry 的 SDK 实现和用途,以及个人对「为什么这么做」的一些浅薄的想法。
1 - 什么是可观测性 (Observability)

写著名「深入理解Java虚拟机」的周志明老师写过一本个人认为同样极其出色的书籍「凤凰架构」[1],在 可观测性 这一章有对这个概念非常棒的总结和解释,这里直接引用一下:
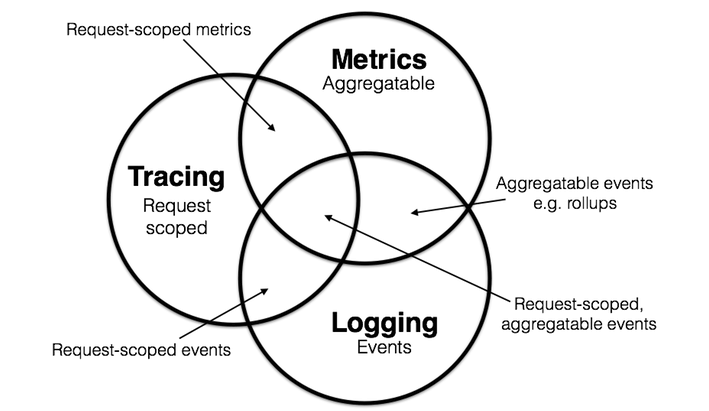
在学术界,虽然“可观测性”这个名词是近几年才从控制理论中借用的舶来概念,不过其内容实际在计算机科学中已有多年的实践积累。学术界一般会将可观测性分解为三个更具体方向进行研究,分别是:事件日志、链路追踪和聚合度量
日志(Logging):日志的职责是记录离散事件,通过这些记录事后分析出程序的行为,譬如曾经调用过什么方法,曾经操作过哪些数据,等等。打印日志被认为是程序中最简单的工作之一,调试问题时常有人会说“当初这里记得打点日志就好了”,可见这就是一项举手之劳的任务。输出日志的确很容易,但收集和分析日志却可能会很复杂,面对成千上万的集群节点,面对迅速滚动的事件信息,面对数以 TB 计算的文本,传输与归集都并不简单。对大多数程序员来说,分析日志也许就是最常遇见也最有实践可行性的“大数据系统”了。
追踪(Tracing):单体系统时代追踪的范畴基本只局限于栈追踪(Stack Tracing),调试程序时,在 IDE 打个断点,看到的 Call Stack 视图上的内容便是追踪;编写代码时,处理异常调用了
Exception::printStackTrace()方法,它输出的堆栈信息也是追踪。微服务时代,追踪就不只局限于调用栈了,一个外部请求需要内部若干服务的联动响应,这时候完整的调用轨迹将跨越多个服务,同时包括服务间的网络传输信息与各个服务内部的调用堆栈信息,因此,分布式系统中的追踪在国内常被称为“全链路追踪”(后文就直接称“链路追踪”了),许多资料中也称它为“分布式追踪”(Distributed Tracing)。追踪的主要目的是排查故障,如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期,等等。度量(Metrics):度量是指对系统中某一类信息的统计聚合。譬如,证券市场的每一只股票都会定期公布财务报表,通过财报上的营收、净利、毛利、资产、负债等等一系列数据来体现过去一个财务周期中公司的经营状况,这便是一种信息聚合。Java 天生自带有一种基本的度量,就是由虚拟机直接提供的 JMX(Java Management eXtensions)度量,诸如内存大小、各分代的用量、峰值的线程数、垃圾收集的吞吐量、频率,等等都可以从 JMX 中获得。度量的主要目的是监控(Monitoring)和预警(Alert),如某些度量指标达到风险阈值时触发事件,以便自动处理或者提醒管理员介入。
2 - 链路追踪 (Distributed Tracing) 是如何进行的
在单体服务的时代,我们仅仅只需要跟踪代码的调用栈就可以获得清晰的调用图关系,以及出现异常时的 Stack Trace。
但在微服务时代,各类服务间可能形态各异(不同语言,不同框架),并通过不同的方式(RPC,HTTP,.etc)进行相互调用。于是如何追踪一次业务级别的服务调用相比单体服务的复杂程度就完全不是一个量级了。
因此我们不仅需要一个统一的「数据表示」来正确的表达这种追踪关系,而且需要一套大而全的「体系规范」来进行程序级别的实现。
Google 在 2010 年发布的这篇论文 Dapper:《Dapper : a Large-Scale Distributed Systems Tracing Infrastructure》[2] 就奠定了之后十余年分布式链路追踪的数据表示的概念,其实抽象出来十分的简单,就是两个基本的概念:
- Trace:一次业务级别的请求调用 (Client <-> Service A <-> Service B <-> … )
- Span:
- 可以是粗粒度的一个 Service 级别的 call
- 也可以是细粒度的 Service 内部的函数调用 (Function A -> Function B -> …)
如何具体的规范化表示和收集这些信息,会在后面详细谈谈。
这里先看看一下在 UI 端,如何展示这些信息:
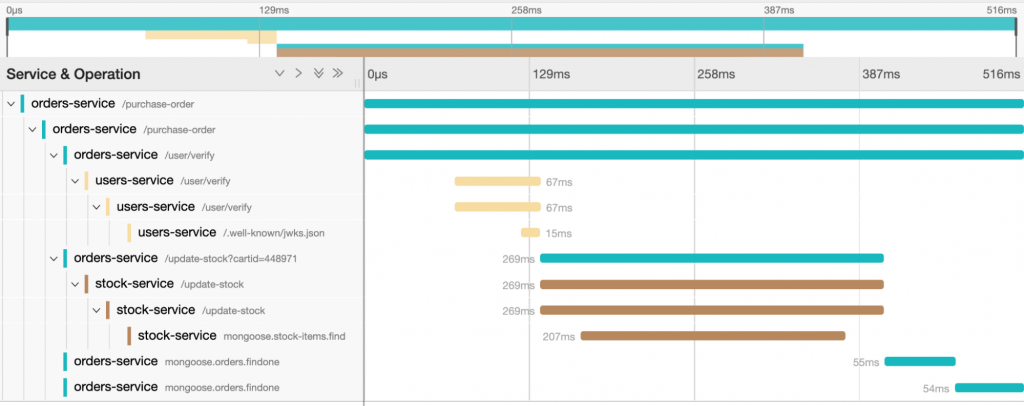
这里是以 Jaeger 为例,展示的一个 Trace Tree,其表示了一个请求/服务调用:
- 花费了多长的时间
- 与哪些内部组件/外部服务进行了交互
- 每个步骤中延迟是多少
可以稍微抽象化一些:
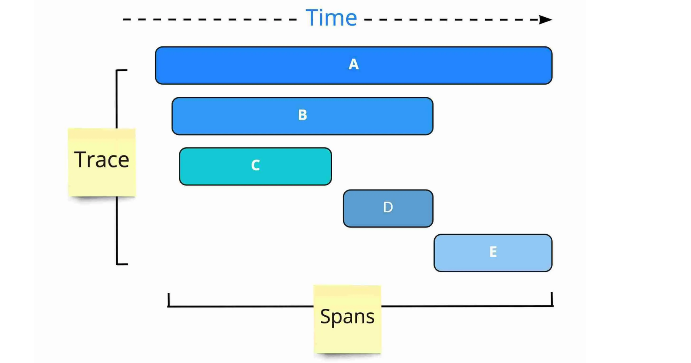
Talk is cheap,用伪代码可以这么表示:
1 | |
这就是「分布式链路追踪」的基本概念,听起来很简单,因为系统的复杂性也确实不在这里。
3 - OpenTelemetry 下的链路追踪
就在前几周,在 v2ex 上看到一个有意思的问题:
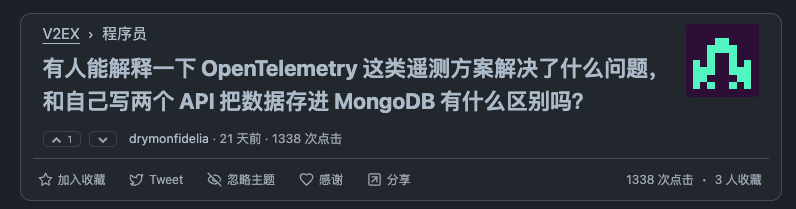
“有人能解释一下 OpenTelemetry 这类遥测方案解决了什么问题,和自己写两个 API 把数据存进 MongoDB 有什么区别吗?"
在结果上,确实没有区别,如果是针对一个小组织的的内部服务,这么做完全可以,但是一但服务多了起来,就需要处理许多的规范化和兼容性问题。
例如,对于异构的服务(来自不同语言,不同平台,不同框架):
- Collect: 如何收集这些信息?格式是什么?
- Export: 如何导出(发送)这些信息?
- Protocol: 用什么协议导出这些信息?
- Persistence: 信息应该存储在哪里?
- UI: 如何统一的进行展示?
这也就是 OpenTelemetry 出现的原因,在 OpenTelemetry 出现之前,几乎市面上所有的追踪系统都是以 Dapper 的论文为原型发展出来的,基本上都算是同门师兄弟,功能上并没有太本质的差距,却又受制于实现细节,彼此互斥,很难搭配工作。譬如该怎样进行埋点、Span 上下文具体该有什么数据结构,怎样设计追踪系统与探针或者界面端的 API 接口,等等,都没有权威的规定。
OpenTelemetry (简称 Otel)的出现,除了统一 Tracing 规范,还一口气把可观测性全部大一统了。光是开箱即用的兼容了 Otel 的 Java Library(可以在 https://github.com/open-telemetry/opentelemetry-java-instrumentation/blob/main/docs/supported-libraries.md 看到)就包含了绝大部分常用的热门框架。即使没有原生支持,也可以通过统一的协议和 SDK 来以较低的成本实现扩展和兼容。
为什么是 OpenTelemetry
为什么各个大厂愿意放弃自己实现的规范和技术架构,跑过来兼容 OpenTelemetry?其实 OpenTelemetry 的统一已经是大厂之间妥协后达成一致的结果,在 Otel 之前,主要有这两种 Tracing 规范标准:
- 在 2016 年,CNCF 技术委员会接受了 OpenTracing 作为基金会第三个项目。(第一个是Kubernetes,第二个是Prometheus)OpenTracing制定了一套平台无关、厂商无关的Trace协议,使得开发人员能够方便的添加或更换分布式追踪系统的实现。OpenTracing 规范公布后,几乎所有业界有名的追踪系统,譬如 Zipkin、Jaeger、SkyWalking (都是 github 20k+ star 的开源项目) 等都很快宣布支持 OpenTracing。
- 这时候大一统本来都要完成统一了,结果google并不认为这个东西是标准,所以推出了自己的 OpenCensus 规范。要是换一家公司来肯定都干不过 OpenTracing 了,但:
- 这可是 Google,要知道最先就是 Google 提出了分布式 Tracing 这个概念。
- OpenCensus 并不是单纯的规范制定,实现了Agent、Collector、SDK 等一系列工具链。
- OpenCensus 又得到了微软的支持。
于是一段时间内都是两架马车并驾齐驱的形势。直到在2019年, 两者和解,共同发起了OpenTelemetry开源项目。最终目标是作为CNCF技术委员会可观测性的终极解决方案,大一统 Tracing,Metrics 和 Logging。[4]
OpenTelemetry 提供了什么
目前 OpenTelemetry 的工作主要集中在如下部分:
- 适用于所有组件的规范 (specification)
- 定义遥测数据形状的标准协议 (protocol)
- 为常见遥测数据类型定义标准命名方案的语义约定 (semantic conventions)
- 定义如何生成遥测数据的 API
- 实现规范、API 和遥测数据导出的SDK
- 实现常见库和框架的仪表化的 Library Ecosystem
- 可自动生成遥测数据的 Auto Instrumentation 组件
- OpenTelemetry Collector:接收、处理和导出遥测数据的代理
同时,可以通过 官方的迁移指南 将 OpenTracing / OpenCensus 迁移到 OpenTelemetry。
Reference
- https://icyfenix.cn/distribution/observability/ ↩
- https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/papers/dapper-2010-1.pdf ↩
- https://www.aspecto.io/blog/what-is-opentelemetry-the-infinitive-guide/ ↩
- https://www.cnblogs.com/zhangmingcheng/p/16720995.html ↩
- https://www.51cto.com/article/665025.html ↩
- https://zhuanlan.zhihu.com/p/74930691 ↩
- https://mp.weixin.qq.com/s?__biz=MzI5ODk5ODI4Nw==&mid=2247487034&idx=1&sn=6055d501703bdc4d399a6de898900758&chksm=ec9c015adbeb884c733793202bf663d543a75b9b26f137e5d8370faa2559703b2e1cb6b15a41&scene=21%23wechat_redirect ↩
- https://opentelemetry.io/zh/docs/what-is-opentelemetry/ ↩